Limite: A Go Server And An Honest Look At LLM-Assisted Development
January 2, 2026Update (2026-01-03)
This project was originally called PDS. It has since been renamed to Limite to better reflect its purpose as a bounded-memory infrastructure system. All concepts and code remain the same.
In these hours I've published PDS Limite, a standalone server written in Go that offers probabilistic data structures. You can find it here. In-memory, of course, which accepts commands via TCP through Redis's RESP protocol and offers a very simple API. Using RESP turned out to be a very convenient choice, since I avoided having to create a dedicated CLI and automatically made this project compatible with every Redis client.
The benchmarks are extremely positive, especially when compared to such a performant product like Redis.
Key-Val
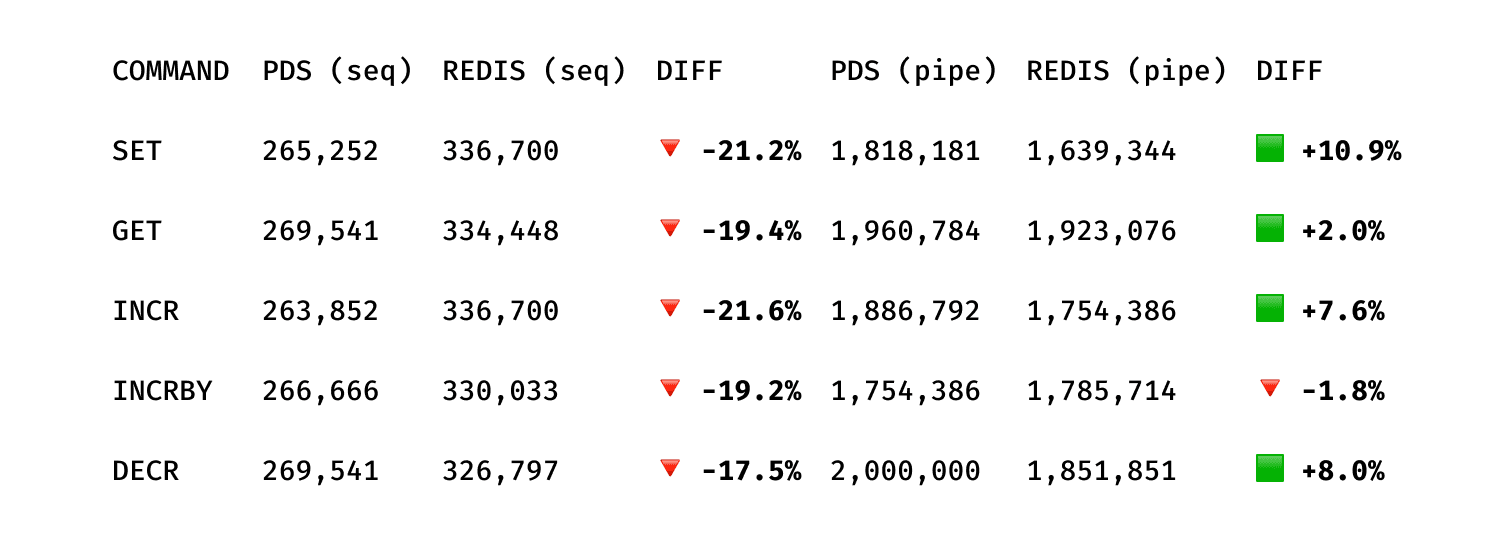
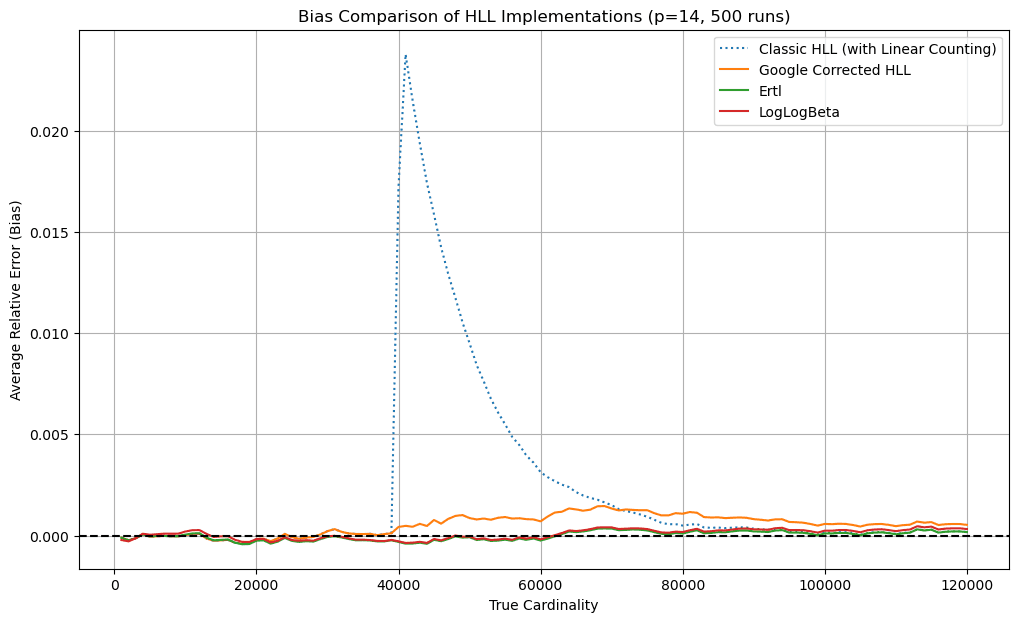
HyperLogLog
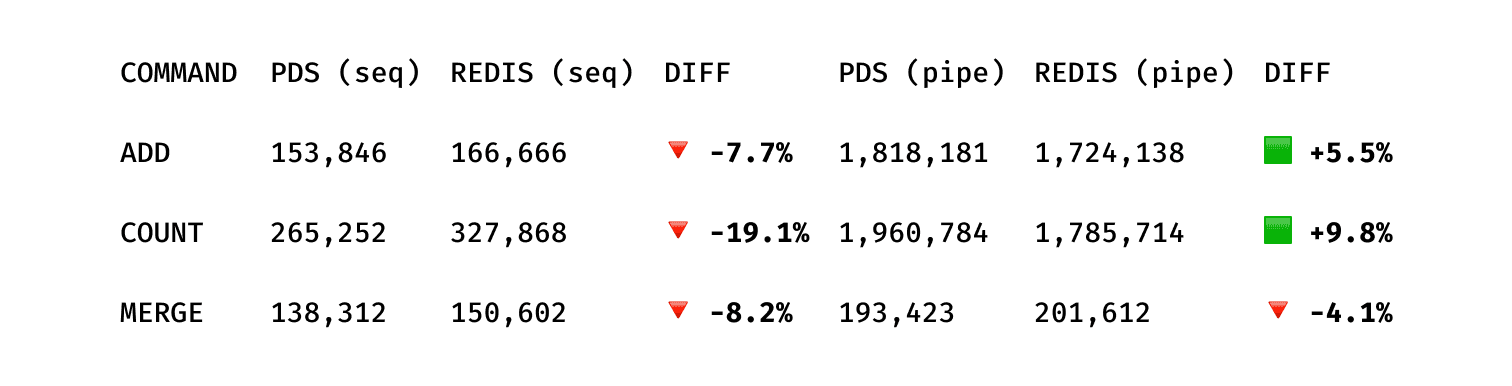
Bloom filter
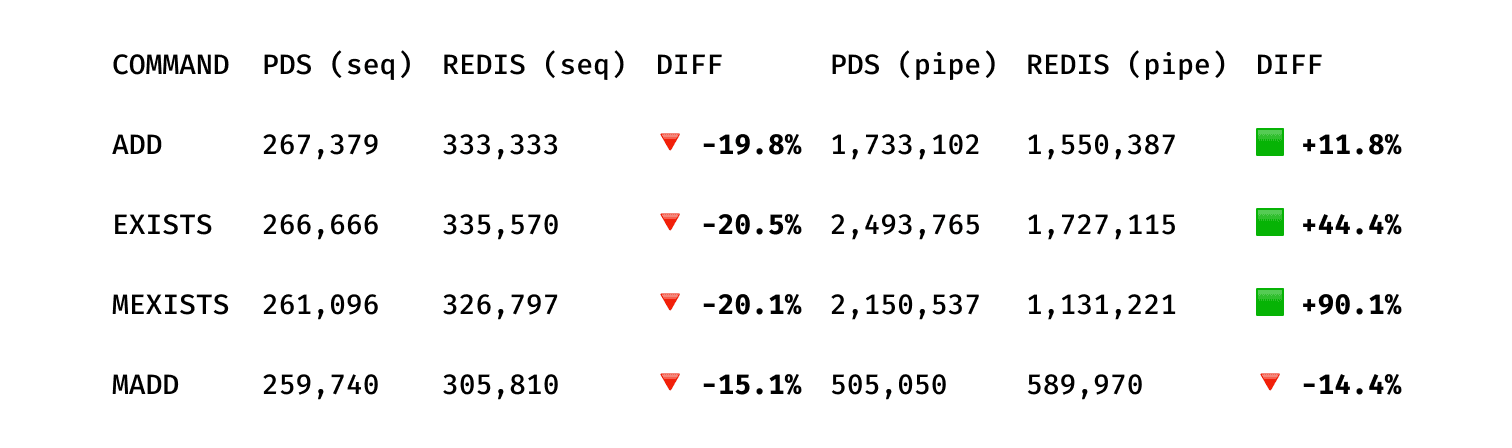
Count-Min Sketch

Top-K
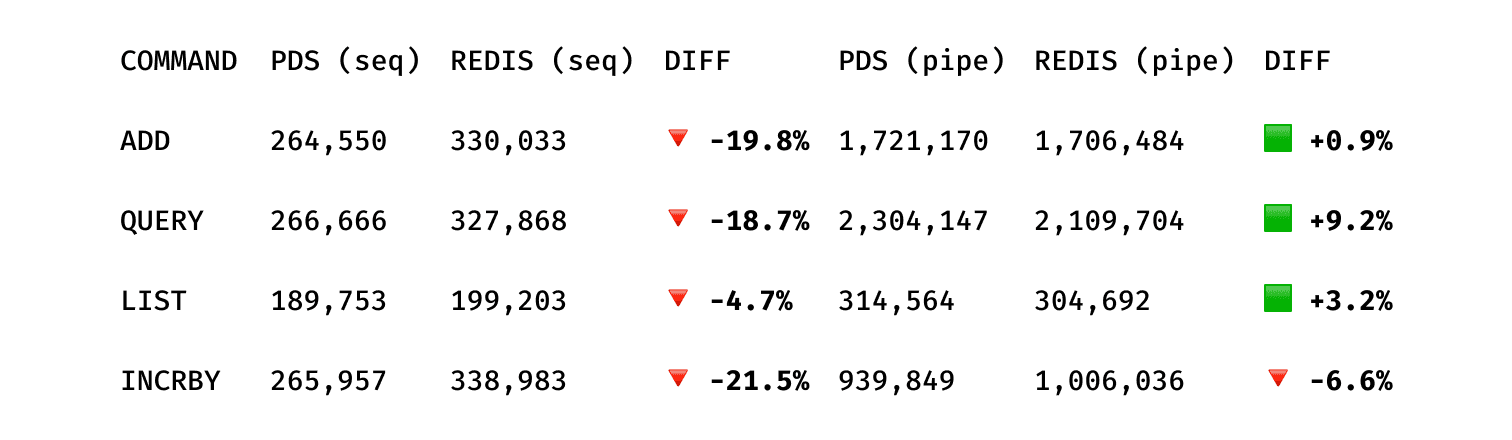
(Benchmarks using redis-benchmark on a VM, Ubuntu Server 24.04.3 LTS, 16GB RAM)
The reason I decided to work on this project is that I was looking for something that had a mathematical component, was relatively low-level, and would force me to read some papers. And I have to say that from this perspective, the choice turned out to be more than spot-on.
But this was also the right opportunity to put LLMs to the test for something more advanced than the usual frontend/backend stuff. And this is what I mainly want to talk about in this post.
First, let's clarify what I developed and what the LLMs developed. The server, the TCP part, and the first data structure HyperLogLog were almost entirely developed by me. I can say the same about the Bloom filter implementation, although there was heavy LLM intervention there. While the entire persistence layer, the limite-check tool, and the last data structures (Count-Min Sketch and Top-K) were entirely made by LLMs.
But let's go in order. First of all, when I say something was "entirely developed by me," I don't mean I didn't use any LLM. I mean the architecture was decided by me and I wrote every line myself. But I still made extensive use of LLMs through their web interfaces, both for the code part (mainly Gemini) and for research (ChatGPT). When I use LLMs this way, they become a sort of super-expert colleague I can bounce ideas off of. I ask for opinions on code and propose ideas and strategies (including architecture). Getting back valuable feedback that improves the final result. The research and study part is also on another level thanks to LLMs. Because it allows me to have a roadmap of topics to dive deeper into.
So, after completing the first part related to the actual server, I moved on to the first algorithm: HyperLogLog. I read the main papers (1, 2 and 3), this post by antirez, and I fed all the information to Gemini to have it explain the most complicated passages. I then created a notebook and implemented the algorithm in Python. The main goal was 1) learn the algorithm and 2) understand the historical evolution of the algorithm by comparing the results of each technique.
Needless to say, this part was very gratifying and represented the peak of my interest in this project.
Then came the integration of the algorithm in Go. At this point I had very clear ideas: I would use Ertl for the cardinality estimation algorithm and 6-bit registers like Redis. Using 6-bit registers is a very elegant solution that forced me to do (and therefore learn) bit masking and to have a more precise understanding of memory and its optimizations. However, it turned out to be a wrong choice for Go, because I ended up with poor performance, especially in the MERGE command. Here Gemini's suggestion to switch to 8-bit registers was crucial, letting me recover over 35% of performance compared to Redis (more info here).
Caught up in the enthusiasm, I decided to tackle a very important chapter before moving on to the new data structure: persistence.
I once again relied on studying Redis and had Gemini create a plan for the implementation. This phase was less "mine," because I limited myself to guiding it and copying what it proposed. Additionally, I launched Claude Code to complete the compaction phase, which now required creating a binary snapshot.
Here began the decline of my interest in this project. The main reason is that I had realized I was essentially making a copy of Redis. So why use my tool and not Redis directly? Sure, I had some ideas in mind to differentiate this project from Redis (I wanted to make it a "magic" insight generator and enable automatic event streaming), but I was starting to doubt these ideas. Moreover, having relied almost blindly on such a delicate part as persistence had marked a point of no return. I no longer felt like I had full ownership of the project.
Anyway, I pushed through and moved on to the new algorithm: Bloom filter. Here, the research wasn't as thorough as what I did for HyperLogLog, and after a first partial draft of the algorithm, I had Claude Code complete the implementation under my supervision. What do I mean? The usual discussions with Gemini to define the architecture and passing this plan (in small steps) to Claude Code. Here we're still in "vibe engineering" territory , so not blind vibe coding. Yet it had already stripped away any kind of satisfaction in producing code.
A little over a month and a half had passed since the first commit at this point, and I had decided I would abandon the project once I implemented the last two data structures I was missing: Count-Min Sketch and Top-K.
Thanks to the combination of Gemini and Claude Code, I integrated Count-Min Sketch in one day. In contrast, Top-K required a couple more days because it had significantly inferior benchmarks compared to the other commands, which were later resolved after several iterations with the aforementioned LLMs.
So, I managed to complete the project in exactly two months. And I have to say it's a remarkable result, considering I worked on it in the evenings on the couch or when I had some free time. I think it would have taken me at least 8 months if I had done it without the help of LLMs.
The entire part where I used the LLM + Human in the loop combo, that is, where I created the actual server and implemented HyperLogLog, took about a month and a half. And it's worth emphasizing, because here we're still talking about drastically reduced times (2x or 3x) but with the benefit of nearly complete knowledge retention, gratification, and ownership. This is still, as far as I'm concerned, the right way to use LLMs.
Whereas, when I switched to mere vibe coding (even if done well), I certainly reduced times by 5x, but this left me with a terrible "impostor" feeling. On the other hand, it allowed me to complete the project and release it, because I had already decided to let it die on my computer. So there was this positive aspect.
So I can understand the interest of big companies in LLMs to cut costs and reduce production times. An example of code produced entirely by LLMs you can see here (packages cms and topk). I'll leave the judgment on the code quality of those two data structures to you.
Final note. One area where LLMs excel is creating tests and the ability to perfectly understand code and generate top-notch comments. And indeed all tests were created by Gemini/Claude Code and the comments by Claude Code.